The Configuration Mistakes That Make Even the Best Infrastructure Vulnerable
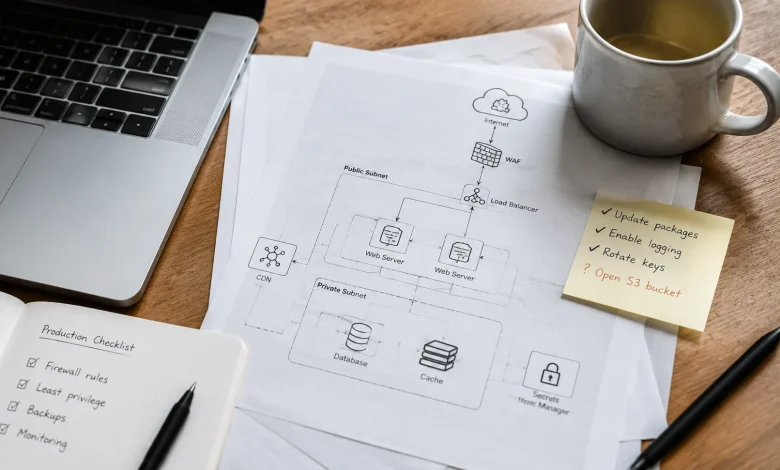
There’s a particular kind of confidence that comes with having the right tools. You’ve selected a reputable cloud provider, hardened your servers, deployed a WAF, put your secrets in a vault, and trained your team on security fundamentals. The architecture diagram looks clean. The audit passed. And then something slips through not because an attacker was sophisticated, but because a single configuration was slightly, quietly wrong.
This is the part of infrastructure security that nobody likes to talk about honestly. The breach doesn’t always arrive through a zero-day exploit or a nation-state adversary. More often, it walks in through a door that was technically closed but left unlocked. The tools were right. The configurations were not.
The Gap Between “Deployed” and “Secured”
Most security tools come with default settings optimized for ease of adoption, not maximum protection. That’s a reasonable product decision nobody would buy software that requires a week of configuration before it does anything. But it creates a systematic trap. Engineers stand up new services under deadline pressure, accept defaults, verify the thing works, and move on. The configuration debt accumulates silently.
Take S3 bucket permissions. Amazon has made bucket policies significantly harder to misconfigure over the years, adding account-level block settings and clearer UI warnings. And yet misconfigured S3 buckets continue to expose sensitive data with startling regularity. Not because engineers don’t know better, but because the gap between “I set up this bucket” and “I verified exactly who can access what under which conditions” is wider than it appears in the moment. The service is up. The feature works. The misconfiguration ages in the background.
The same dynamic plays out with Kubernetes RBAC, IAM role trust policies, security group rules, and network ACLs. The component is deployed; the security posture of that component is a separate question that often gets answered much later, if at all.
Overpermissioned Everything
Least-privilege is one of those principles that everyone agrees with and almost nobody implements consistently. The practical reason is simple: it’s much faster to grant broad access and troubleshoot permissions by removing them than to enumerate exactly what a service needs from day one. Under sprint pressure, “give it admin for now and we’ll lock it down later” is a statement that starts as a pragmatic workaround and ends as permanent policy.
The impact compounds in ways that aren’t obvious until something goes wrong. An overpermissioned service account gets compromised. The attacker doesn’t just affect that service they can pivot across everything that account had access to. What should have been a contained incident becomes a full lateral movement scenario.
IAM roles attached to EC2 instances are a particularly common example. The metadata service makes those credentials trivially accessible to any process running on the instance. If that role has broad S3 access, or worse, permission to assume other roles, a single SSRF vulnerability anywhere in your application stack becomes a skeleton key. The vulnerability isn’t novel. The blast radius is purely a function of how generously that role was configured.
Logging That Doesn’t Actually Help You
Logging is another area where the gap between presence and utility is enormous. Most teams enable logging. Fewer teams have logging that would actually tell them something meaningful during an incident.
The common pattern is enabling access logs but not enabling the specific log types that capture authentication events, privilege escalation attempts, or lateral movement. CloudTrail might be on but not configured to capture data events. VPC Flow Logs might be enabled but routing to a destination nobody monitors. Log retention might be set to seven days, which sounds reasonable until you’re trying to reconstruct what happened three weeks ago.
There’s also the configuration mistake of insufficient log granularity. Knowing that a Lambda function was invoked is different from knowing what it was invoked with and what it returned. Knowing that a database was queried is different from knowing which queries ran against which tables under what credentials. The former satisfies compliance checklists; the latter actually supports forensics.
The subtler version of this problem is storing logs in a location that an attacker who compromises your account can also access and delete. Logs that are retained in the same account they’re generated in, without write protection or replication to an isolated account, are a configuration oversight that can turn a detectable incident into an unrecoverable one.
Network Boundaries That Exist on Paper
Security groups and network ACLs create the appearance of network segmentation without necessarily delivering its substance. The appearance comes from the fact that rules exist. The substance depends entirely on what those rules actually permit.
A database subnet that is supposed to be private but has a security group rule allowing inbound traffic on port 5432 from 0.0.0.0/0 is not private in any meaningful sense. Neither is an internal service that allows inbound connections from an entire VPC CIDR rather than the specific services that actually need to reach it. The intent was segmentation. The implementation was not.
This pattern often originates from debugging sessions. An engineer can’t figure out why two services aren’t communicating, opens the security group rule temporarily, the problem resolves, and the broad rule never gets tightened. Multiply this across a team over two years and you have a network topology where the segmentation boundaries exist as diagrams and documentation but not as enforced technical controls.
The same logic applies to outbound rules. Outbound access is frequently left completely unrestricted because restricting it requires knowing what each service legitimately needs to reach, which requires effort nobody wants to invest. But an attacker who achieves code execution on a system with unrestricted outbound access can exfiltrate data and establish command-and-control channels without fighting any additional controls.
Secrets That Aren’t Really Secret
The vault is deployed. The secrets are rotated. And somewhere in a CI/CD pipeline, an environment variable contains a hardcoded database password because it was easier to test that way and nobody cleaned it up.
Or the secrets manager integration is working correctly for the application, but the configuration management system stores the seed credential used to bootstrap access to the secrets manager in a git repository. The vault is secure; the key to the vault is not.
Or rotation is enabled, but the application isn’t designed to handle credential rotation gracefully, so when the secret rotates, the application breaks, and in the post-incident scramble someone sets the rotation interval to three years to stop the alerts.
These aren’t failures of the tools. They’re configuration failures decisions made in context that seem locally reasonable but produce systemic exposure. The secret management system can be exactly the right product, configured in a way that leaves your most sensitive credentials effectively unprotected.
The Drift Problem
Even when a configuration starts correct, it doesn’t stay that way without active effort. Infrastructure changes. New services get added. Existing services get modified to meet new requirements. Configurations drift.
A security group that was appropriately scoped in January gets an extra rule in March to unblock a vendor integration and a different extra rule in June to support a new service that later gets deprecated but whose security group rule doesn’t get cleaned up. By December, the effective policy bears little resemblance to the intended policy. Nobody made a single bad decision; the accumulation of locally reasonable decisions produced a systemically bad outcome.
This is why infrastructure-as-code and continuous compliance scanning matter beyond their immediate utility. IaC creates a reference point what the configuration is supposed to be. Continuous scanning measures the delta between what’s supposed to be true and what is actually true right now. Without both, configuration drift is invisible until it surfaces as an incident.
The most dangerous configuration mistake isn’t any single error. It’s the assumption that security is a state you achieve rather than a condition you continuously maintain. The tools can be exceptional. The architecture can be sound. What determines whether infrastructure holds is whether the configurations that govern it are treated with the same rigor as the code that runs on it.




